AI Project
VisionText
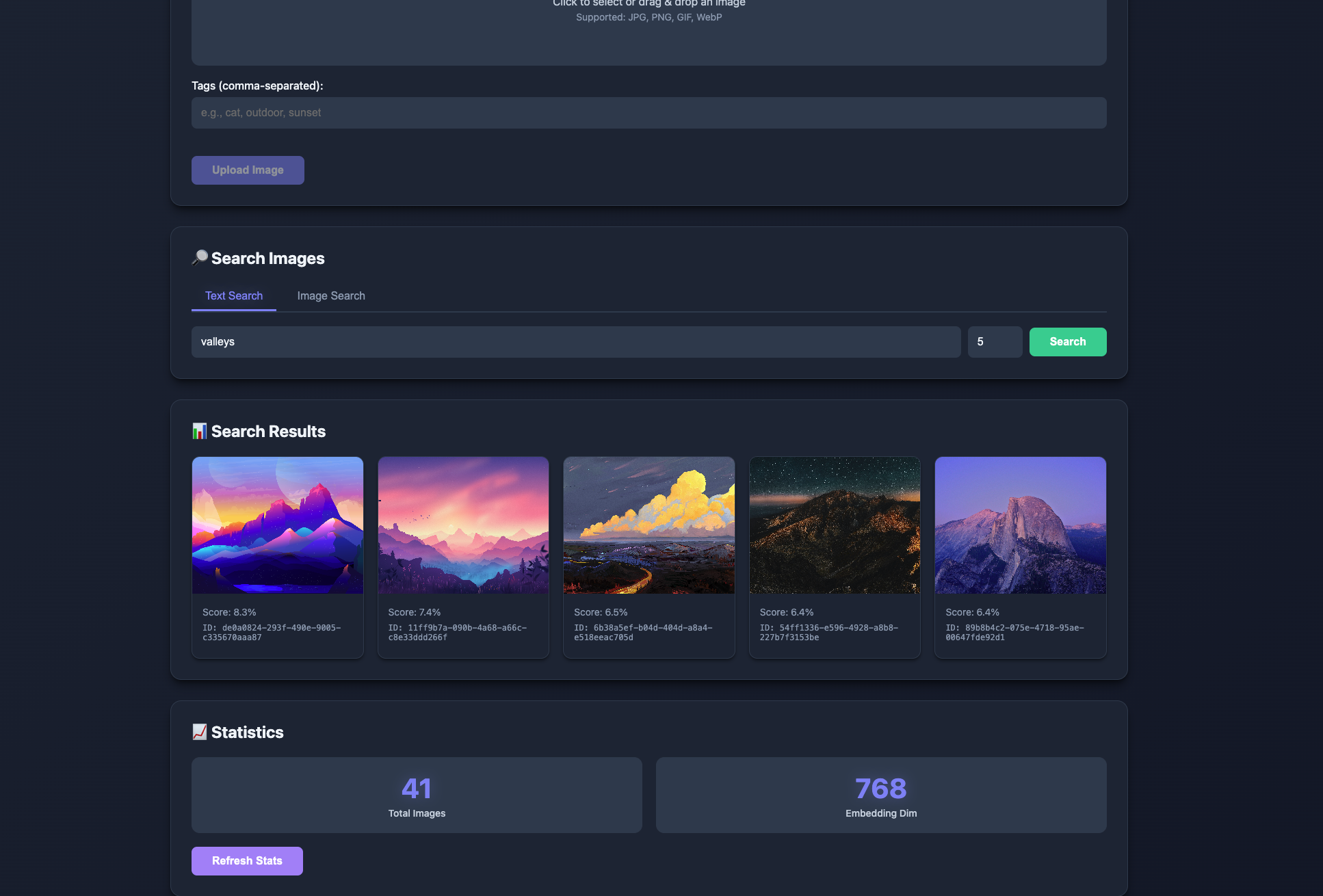
Multi-modal image search system using CLIP embeddings and Qdrant vector database. Supports text-to-image and image-to-image search with hybrid ranking pipeline using RRF. Includes batch processing, async API, and a modern web UI. Dockerized for easy deployment. View code.
Technologies:
- Python
- FastAPI
- CLIP (SigLIP)
- Qdrant
- Docker